
Introduction
In today's digital age, Over-The-Top (OTT) platforms like Netflix, Amazon Prime Video, Disney+, and Hulu have emerged as crucial entertainment hubs, offering a diverse range of movies, TV shows, and original content. OTT data scraping can be highly valuable for competitive analysis, content aggregation, and developing recommendation systems by scraping content from these platforms. However, scraping streaming data from OTT platforms presents unique challenges and requires careful consideration of legal and ethical guidelines.
To effectively scrape content from OTT platforms, choosing the right tools and technologies, such as web scraping libraries, APIs, and headless browsers, is essential. Navigating dynamic content and handling obstacles like CAPTCHAs and rate limits are also crucial. Additionally, ethical practices, such as respecting user privacy and platform policies, are vital to ensure responsible data use. Following a well-structured approach to OTT data extraction, you can successfully extract and utilize streaming data for various analytical purposes while maintaining compliance with industry standards.
Understanding the Legal and Ethical Considerations

Before using an OTT data scraper, it's essential to understand the legal and ethical implications. OTT platforms like Netflix , Amazon Prime Video, and others often have strict terms of service that prohibit unauthorized data extraction. Using a streaming data scraper without adhering to these terms can result in serious legal consequences, including potential lawsuits or being banned from the platform. To avoid these risks, always ensure your data scraping activities comply with the platform's terms and conditions. In some cases, it might be advisable to seek permission from the platform before proceeding with data scraping. This helps you avoid legal issues and demonstrates a commitment to ethical practices. By respecting the platform's guidelines, you can responsibly use OTT data scraping services for competitive analysis, content aggregation, or other legitimate purposes without violating rules.
Ethical Considerations
• Respect user privacy and data protection laws.
• Use the scraped data responsibly and avoid misuse.
• Be mindful of the impact of your scraping activities on the platform's performance.
Identifying the Target Data
Determine what specific data you want to scrape. Common data types from OTT platforms include:
• Movie/TV Show Details: Titles, descriptions, cast, genre, release dates, ratings.
• Streaming Availability: Information about where content is available for streaming.
Aggregate data on user feedback.Aggregate data on user feedback.
• Pricing and Subscription Plans: Details on different subscription tiers and pricing.
Selecting the Right Tools and Technologies
To scrape data from OTT platforms, you'll need specific tools and technologies:
• Web Scraping Libraries: Tools like Beautiful Soup, Scrapy, and Selenium can help you navigate and extract data from web pages.
• APIs: Some OTT platforms offer APIs that provide structured access to their data. Always check the availability of official APIs.
• Headless Browsers: Tools like Puppeteer or Playwright help scrape dynamic content that requires interaction.
Setting Up Your Environment
1. Install Required Libraries: Ensure you have the necessary libraries installed. For example, if you're using Python, you might need:
pip install beautifulsoup4 requests selenium
2. Choose a Programming Language: Python is commonly used due to its robust libraries, but other languages like JavaScript (with Node.js) or Ruby can also be used.
3. Set Up a Development Environment: Use a code editor like VSCode or PyCharm to manage and run your scraping scripts.
Writing the Scraper
1. Basic Web Scraping:
Here's a simple example using Python with Beautiful Soup and Requests:

2. Handling Dynamic Content:
For platforms that load content dynamically using JavaScript, use Selenium:

3. Using APIs:
If an API is available, use it to fetch data:

Managing Challenges and Troubleshooting
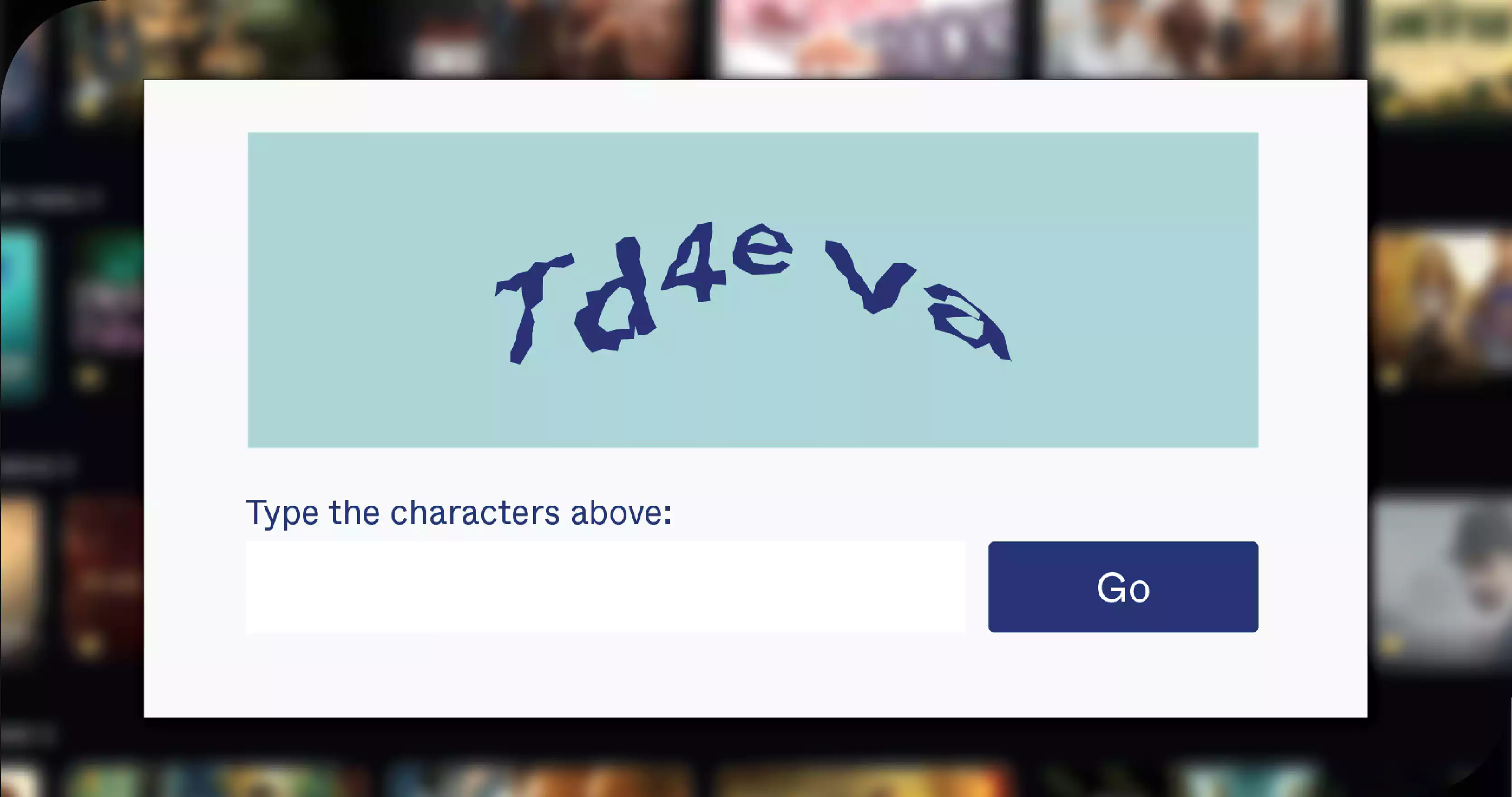
1. Handling CAPTCHAs: Some platforms use CAPTCHAs to prevent automated access. Solutions include using CAPTCHA-solving services or avoiding too many requests in a short period.
2. Rate Limiting: Respect the platform's rate limits. Implement delays or use proxies to avoid being blocked.
3. Data Format Changes: Monitor the platform for changes in the HTML structure or API endpoints, which may require adjusting your scraper.
Storing and Analyzing Data
1. Storing Data: Save the scraped data to a database or file system. Standard formats include CSV, JSON, or SQL databases.
2. Analyzing Data: Use data analysis tools to process and visualize the data. Python libraries like Pandas and Matplotlib can help with analysis and visualization.
Best Practices for Scraping OTT Platforms
1. Respect Robots.txt: Check the robots.txt file of the website to see which pages or sections are allowed to be scraped.
2. Avoid Overloading Servers: Implement delays between requests to avoid excessive load on the platform's servers.
3. Regularly Monitor and Update: Continuously monitor your scraping scripts and update them as needed to adapt to platform changes.
Future Trends and Considerations for OTT Media Data Scraping

As the demand for data-driven insights continues to grow, the future of scraping OTT media data is set to evolve significantly. Advanced technologies like artificial intelligence (AI) and machine learning (ML) are expected to enhance the efficiency and accuracy of scraping OTT media data. These technologies can help automate complex tasks, such as identifying patterns in large datasets and predicting user behavior, making streaming data scraping services more sophisticated and valuable.
Another key trend is the increasing emphasis on data privacy and security. With stricter regulations like GDPR and CCPA, companies offering streaming data scraping services must prioritize compliance and ethical data usage. This includes implementing measures to protect user privacy and ensuring data scraping practices do not violate legal guidelines.
Moreover, OTT platforms are likely to implement more advanced anti-scraping technologies, making it essential for data scrapers to stay updated with the latest tools and techniques. As these platforms evolve, so will the challenges associated with scraping OTT media data, requiring continuous innovation and adaptation. Maintaining a balance between adequate data scraping and adhering to legal and ethical standards will be critical for future success in this dynamic landscape.
Conclusion
Scraping content from OTT platforms can provide valuable insights and enhance your understanding of the digital entertainment landscape. However, it requires careful planning, adherence to legal and ethical guidelines, and appropriate tools and techniques. By following this step-by-step guide, you can effectively scrape data while respecting the platform's policies and ensuring the responsible use of the gathered information. Whether you're performing competitive analysis, building recommendation systems, or aggregating content, these practices will help you navigate the complex world of OTT data scraping.
Embrace the potential of OTT Scrape to unlock these insights and stay ahead in the competitive world of streaming!