
In the digital age, Over-the-Top platforms like Netflix, Hulu, Disney+, and Amazon Prime have changed how we devour media. These platforms offer a wide range of content, from movies and TV shows to exclusive series and documentaries. As the OTT market grows, there's a burgeoning interest in scraping data from these platforms. Scraping OTT apps using Python provides valuable insights into user behavior, content trends, and competitive analysis. This article delves into the techniques and use cases of OTT apps data scraping using Python.
What is App Scraping?
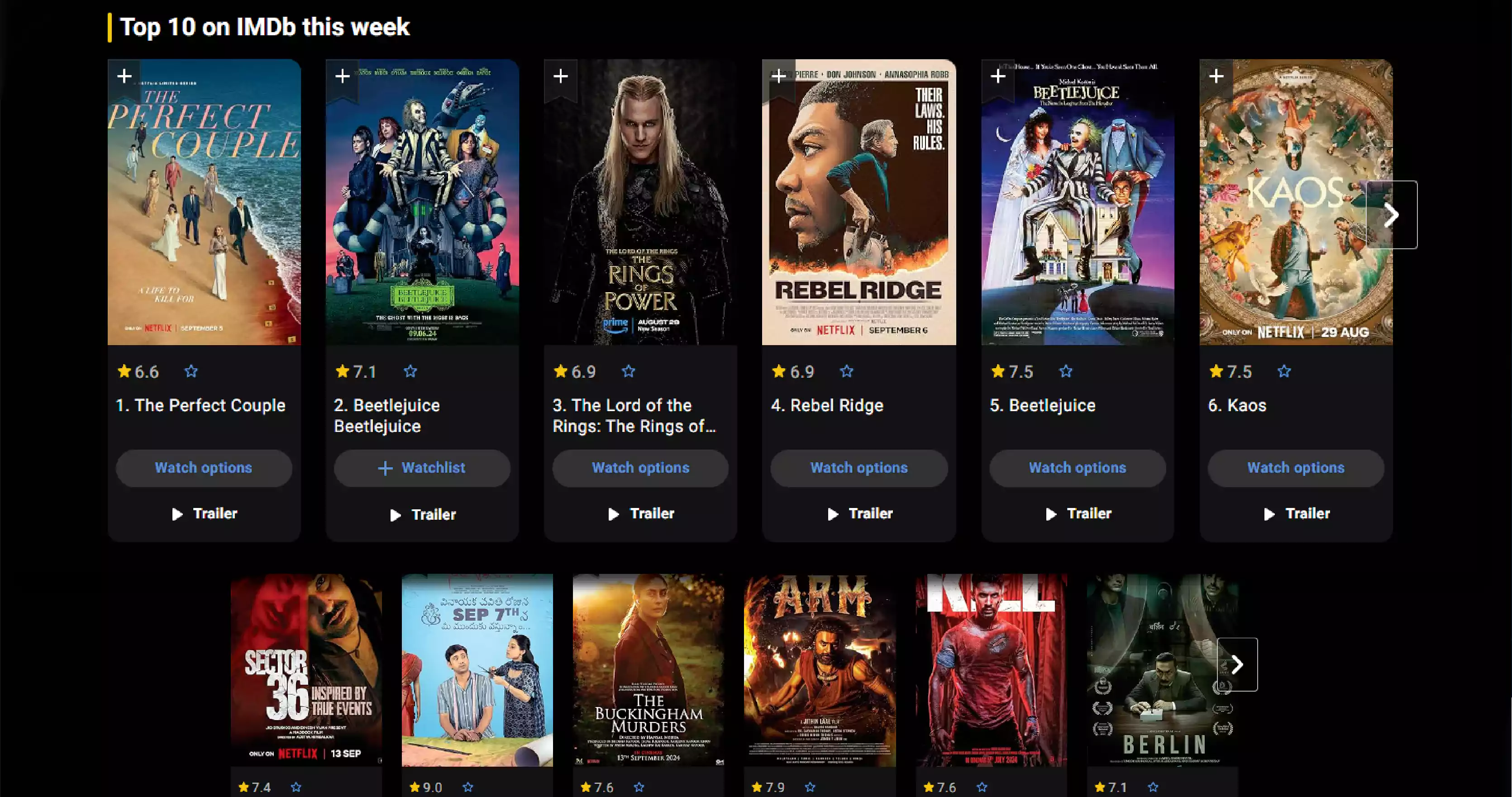
App scraping is the process of extracting data from mobile applications. This technique is widely used to collect information from various sources, which can then be analyzed for trends, patterns, and insights. For OTT apps, scraping streaming data can involve gathering data on content ratings, viewer reviews, release dates, and much more.
Why Scrape OTT Apps?
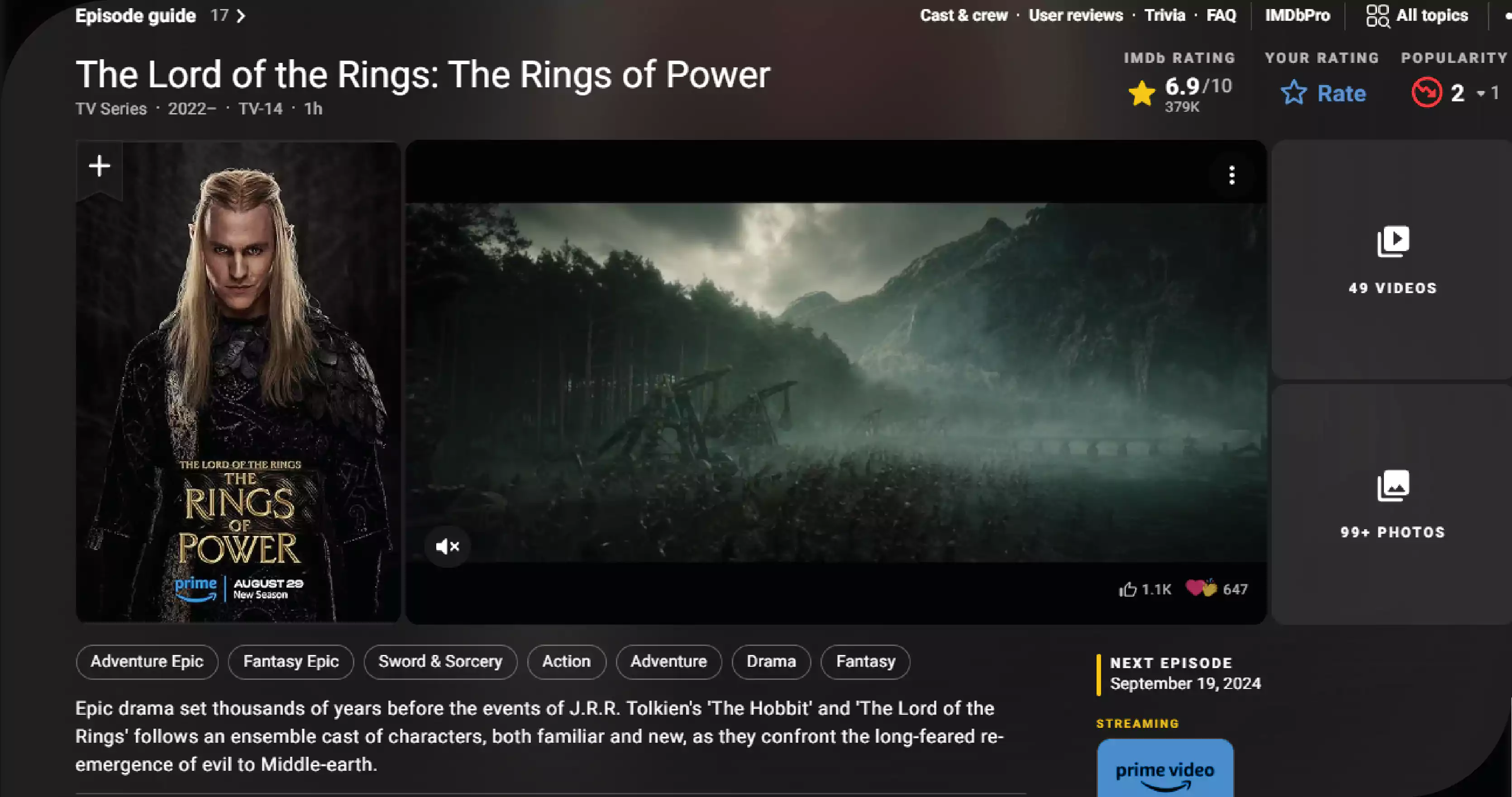
Scraping OTT apps unlocks valuable insights into viewer preferences, content trends, and competitive strategies. By gathering data on ratings, reviews, and content offerings, businesses can make informed decisions, optimize their content strategies, and stay ahead in the competitive streaming market.
1. Content Analysis: Analyzing content data using OTT data scraping services helps understand what genres or shows are trending.
2. Competitive Intelligence: Businesses can adjust their offerings accordingly by scraping competitors' content libraries, pricing, and promotional strategies.
3. Viewer Insights: An OTT data scraper can collect data on viewer ratings and reviews to help understand audience preferences.
4. Market Research: Data from OTT platforms can provide insights into market dynamics and content performance.
Tools and Libraries for Scraping with Python
Python offers several powerful libraries and tools for scraping OTT app data. The most commonly used include:

• BeautifulSoup: A library for parsing HTML and XML documents. It helps in extracting data from pages.
• Scrapy: An open-source framework for scraping that provides a robust structure for creating crawlers.
• Selenium: A tool for automating browsers. It is beneficial for scraping content from dynamic pages.
• Requests: A library for making HTTP requests, which can be used to fetch pages.
• Pandas: While not a scraping tool per se, Pandas is invaluable for data manipulation and analysis post-scraping.
Techniques for Scraping OTT Apps
To scrape OTT app data using Python, follow these steps. For this example, I'll assume you're scraping public data from a website (not through an API) and using BeautifulSoup and requests for simplicity. Ensure you comply with the terms of service and robots.txt file.
1. Install Required Libraries
First, install the necessary Python libraries:
pip install requests beautifulsoup4
2. Import Libraries
In your Python script or Jupyter Notebook, import the required libraries:
import requests
from bs4 import BeautifulSoup
3. Define the URL
Specify the URL of the OTT app's page you want to scrape:
url = 'https://example-ott-app.com/movies'
4. Send HTTP Request
Use the requests library to send an HTTP request to the URL:
response = requests.get(url)
5. Check Response Status
Ensure the request was successful by checking the status code:

6. Parse the HTML
Use BeautifulSoup to parse the HTML content:
soup = BeautifulSoup(response.content, 'html.parser')
7. Extract Data
Identify the HTML elements that contain the data you need. For example, if you want to extract movie titles and descriptions:

8. Handle Pagination (if needed)
If the data spans multiple pages, find and navigate through pagination links:
.web)
9. Store Data
Save the extracted data to a file or database. For example, saving to a CSV file:

10. Handle Exceptions and Errors
Add error handling to manage potential issues:

11. Respect Robots.txt and Rate Limiting
Ensure you respect the robots.txt file and implement rate limiting to avoid overwhelming the server. You can use time.sleep() to pause between requests:
import time
time.sleep(2) # Sleep for 2 seconds
Example Code

Use Cases of Scraping OTT Apps
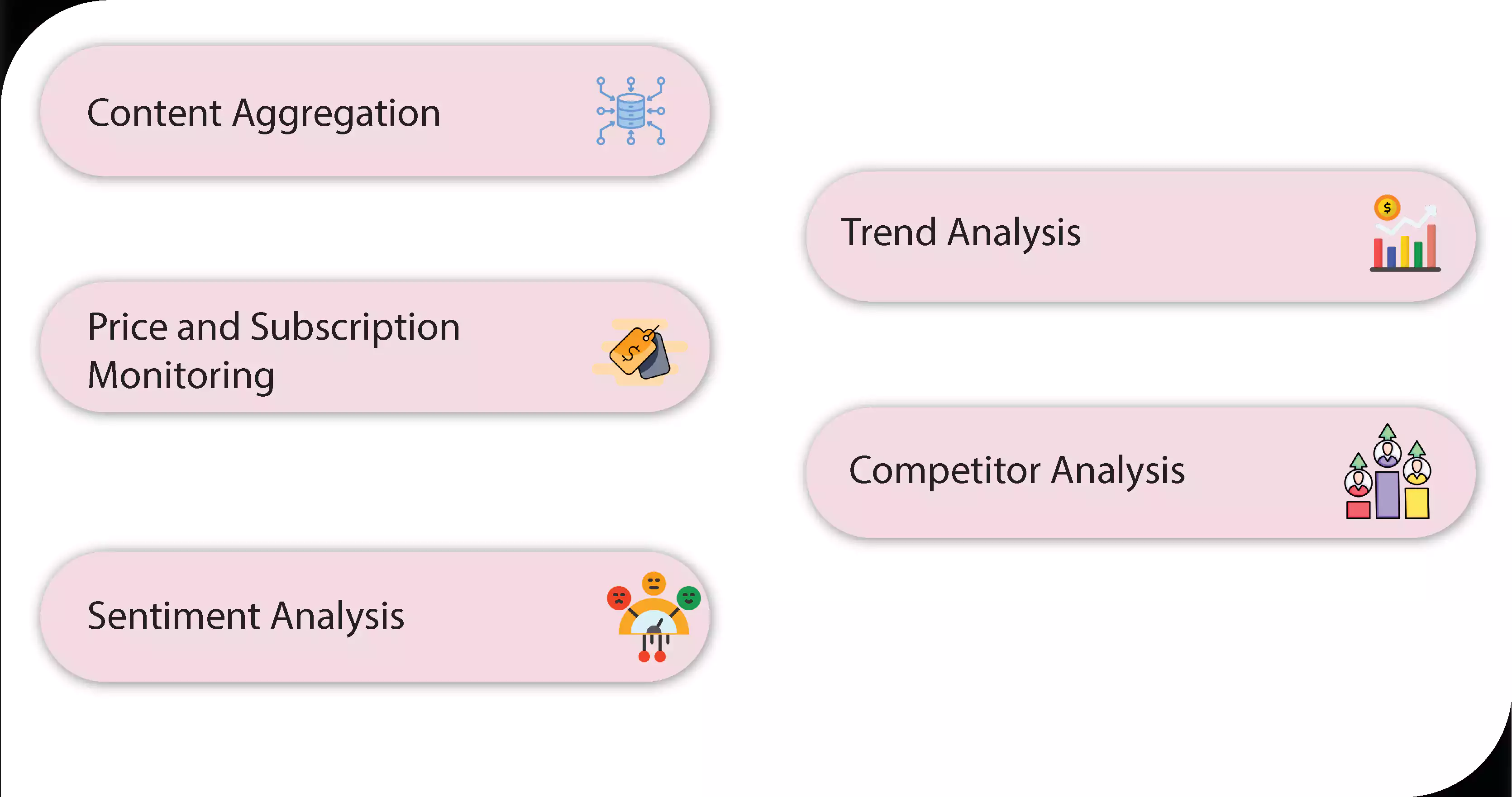
Scraping OTT apps offers diverse use cases, from aggregating content and monitoring subscription trends to performing sentiment analysis and competitive benchmarking. These applications provide critical insights into market dynamics, user preferences, and emerging trends, driving strategic decisions in the streaming industry.
1. Content Aggregation
Content aggregation involves compiling data from various OTT platforms into a single repository. This helps create comprehensive databases of movies and shows, which can be used for comparison and recommendation engines.
Example: An app aggregating content from Netflix, Hulu, and Amazon Prime to offer users a single search interface for finding where a particular movie or show is available.
2. Price and Subscription Monitoring
OTT platforms often have different subscription tiers and pricing models. Scraping data about these models can help in monitoring changes over time.
Example: Analyzing the subscription price trends across different platforms to identify which service offers the best value for money.
3. Sentiment Analysis
Businesses can perform sentiment analysis to gauge public opinion about specific shows or movies by scraping user reviews and ratings.
Example: Analyzing reviews of a new release to predict its success and recommend similar content to users.
4. Trend Analysis
Tracking the popularity of various genres, directors, and actors can provide insights into emerging trends in the entertainment industry.
Example: Identifying rising stars or trending genres by analyzing data on the most-watched shows or movies over time.
5. Competitor Analysis
Competitive intelligence involves scraping data from rival OTT platforms to understand their content strategy, pricing, and promotional activities.
Example: Comparing the content libraries and pricing structures of different OTT platforms to refine one's content offerings and pricing strategies.
Legal and Ethical Considerations
When scraping data from OTT apps, it is crucial to adhere to legal and ethical guidelines:
• Respect Robots.txt: Check if the site's robots.txt file disallows scraping.
• Avoid Overloading Servers: Implement rate limiting to avoid overwhelming the servers.
• Comply with Terms of Service: Ensure that scraping activities do not violate the platform's terms of service.
• Data Privacy: Be cautious about scraping personal data and ensure compliance with data protection regulations.
Conclusion
Scraping OTT apps using Python provides valuable insights and data for various purposes, including content analysis, competitive intelligence, and trend monitoring. Businesses and researchers can extract and analyze data to make informed decisions by leveraging Python's powerful libraries and tools. However, it's essential to navigate the legal and ethical landscape carefully to ensure that scraping activities are conducted responsibly.
As the OTT landscape continues to evolve, harnessing data effectively will be crucial for staying competitive and understanding audience preferences. With Python's versatility and the proper techniques, scraping OTT apps can become a powerful tool in any data-driven strategy.
Embrace the potential of OTT Scrape to unlock these insights and stay ahead in the competitive world of streaming!