
Introduction
In an era where streaming services dominate the entertainment landscape, Netflix is a global leader. With millions of subscribers and an extensive content library, Netflix is a goldmine of data for analysts, developers, and researchers. Whether it's for creating recommendation systems, understanding viewer behavior, or analyzing trends in content consumption, scraping Netflix data has become an essential task for many in the tech industry. This article delves into the complexities, challenges, and ethical considerations of scraping Netflix data using Python, offering insights beyond the technical steps and tools typically discussed.
The Value of Netflix Data

Netflix data is precious because it reflects real-time viewer preferences and consumption patterns. The platform's recommendation algorithms, often cited as some of the most advanced in the industry, rely heavily on data collected from user interactions. This data includes viewing history, search queries, ratings, and even the time spent watching certain types of content.
For data scientists and engineers, Netflix data scraping can provide a wealth of information that can be used to improve recommendation engines, analyze trends, and develop new features. For marketers and advertisers, this data can help them understand audience segments and target ads more effectively. Researchers can use the data to study the impact of certain genres, actors, or even societal events on viewing habits.
However, accessing this data takes more work. Netflix's APIs are limited and only provide some of the necessary information. This is where web scraping comes into play.
Challenges in Scraping Netflix Data
Streaming data scraping is more complex than it might be for other websites. The platform is designed with several layers of security and anti-scraping mechanisms that make it challenging to extract Netflix data without being detected or blocked. Here are some of the key challenges:
1. Dynamic Content: Netflix uses JavaScript to load content dynamically. This means that much of the data is not in the HTML source code but is loaded asynchronously when the user interacts with the page. Scraping such dynamic content requires more advanced techniques, such as rendering JavaScript or using headless browsers.
2. Anti-Scraping Measures: Netflix has implemented various anti-scraping measures, including CAPTCHA challenges, IP blocking, and rate limiting. These measures are designed to detect and block automated scraping tools, making it difficult to extract large amounts of data without getting blocked.
3. Legal and Ethical Considerations: Scraping data from Netflix raises several legal and ethical questions. While scraping publicly available data is generally legal, scraping data behind a login wall or using automated tools to bypass security measures can violate Netflix's terms of service. Additionally, there are ethical concerns around privacy and data usage, especially when dealing with user-generated content.
Understanding Netflix's Data Structure
Before attempting to scrape Netflix data, it is crucial to understand the platform's data structure. Netflix organizes its content into various categories, such as genres, new releases, and trending shows. Each piece of content has associated metadata, including title, description, cast, genre, and more. This metadata is often loaded dynamically and may require multiple requests to different endpoints to collect all relevant information.
Moreover, Netflix extensively uses personalized recommendations, meaning that the content displayed on the homepage or in specific categories may differ between users. This personalization is based on user profiles, viewing history, and other factors, making obtaining a consistent dataset across different accounts challenging.
The Importance of Proxy Management

Given Netflix's robust anti-scraping measures, managing proxies effectively is crucial when scraping data from the platform. A proxy acts as an intermediary between the scraper and the target website, masking the scraper's IP address and allowing it to bypass certain restrictions. However, not all proxies are created equal, and using free or low-quality proxies can lead to IP bans or detection by Netflix's anti-scraping mechanisms.
Rotating proxies, which change the IP address after each request, are often used to avoid detection. This method ensures that requests appear from different users, reducing the likelihood of being blocked. Additionally, using residential proxies, IP addresses assigned to real devices by internet service providers, can make the scraping activity appear more legitimate.
Navigating CAPTCHA Challenges

CAPTCHAs are one of Netflix's most common anti-scraping measures. These challenges are designed to distinguish between human and automated traffic by presenting tests that are easy for humans but difficult for bots to solve. Solving CAPTCHAs automatically is a significant challenge in web scraping and often requires advanced techniques, such as using third-party CAPTCHA-solving services or machine learning models.
Another approach to dealing with CAPTCHAs is to minimize the frequency of requests to avoid triggering them in the first place. This can be achieved by slowing the scraping process, randomizing request intervals, and using multiple accounts or proxies.
Dealing with Dynamic Content

As mentioned earlier, Netflix uses JavaScript to load content dynamically, which presents a challenge for traditional web scraping methods that rely on parsing static HTML. To scrape dynamic content, one must use techniques that can render JavaScript, such as headless browsers or browser automation tools.
Headless browsers, like Puppeteer or Playwright, are popular choices for scraping dynamic content. These tools allow the scraper to interact with the page as a real user, clicking buttons, scrolling, and waiting for content to load. At the same time, headless browsers are powerful but resource-intensive and slower than traditional scraping methods. Therefore, they should be used judiciously, especially when scraping extensive data.
Ethical Considerations in Scraping Netflix Data

Scraping Netflix data is not just a technical challenge; it also raises important ethical questions. While scraping publicly available data is generally considered ethical, the line becomes blurred when dealing with data behind a login wall or using techniques to bypass anti-scraping measures. Here are some key ethical considerations:
1. Respect for Privacy: Netflix users have a reasonable expectation of privacy, especially regarding their viewing habits and personal data. Scraping data that includes personally identifiable information (PII) or user-generated content can violate privacy and is generally considered unethical.
2. Compliance with Terms of Service: The Netflix data scraper may violate the platform's terms of service, explicitly prohibiting automated data extraction. While terms of service are not legally binding contracts, violating them can lead to account suspension, IP bans, or even legal action.
3. Data Usage: The purpose for which the scraped data is used also matters. Using scraped data for malicious purposes, such as spamming, phishing, or creating fake accounts, is unethical and potentially illegal. On the other hand, scraped data using Netflix data scraping services for research, analysis, or improving services can be justified if done responsibly.
Alternatives to Scraping: Netflix's API
While web scraping is a powerful technique, there are better approaches for obtaining data from Netflix. The platform offers limited access to its data through APIs, which are designed for developers and partners. These APIs provide a more structured and reliable way to access certain data types, such as catalog information, user recommendations, and playback statistics.
Using Netflix's API has several advantages over scraping, including:
• Reliability: APIs are designed to handle large volumes of requests and provide consistent data, unlike web scraping, which can be affected by changes in the website's structure or anti-scraping measures.
• Legal Compliance: Accessing data through an API generally complies with the platform's terms of service, reducing the risk of account suspension or legal action.
• Efficiency: APIs are often more efficient than scraping, as they provide direct access to the data without the need to parse HTML or render JavaScript.
However, the Netflix API is limited in scope and may only provide some of the data that a scraper might need. In such cases, a hybrid approach can be an effective solution, combining API access with selective scraping.
Steps to Scrape Netflix Data Using Python
Here’s a step-by-step guide to scraping Netflix data with Python, including sample code snippets:
1. Define Objectives
Decide what data you want to scrape from Netflix, such as movie titles, genres, or ratings.
2. Inspect Netflix's Web Structure
Use browser developer tools (right-click on the page and select "Inspect") to understand the HTML structure of the data you want to extract.
3. Handle Authentication
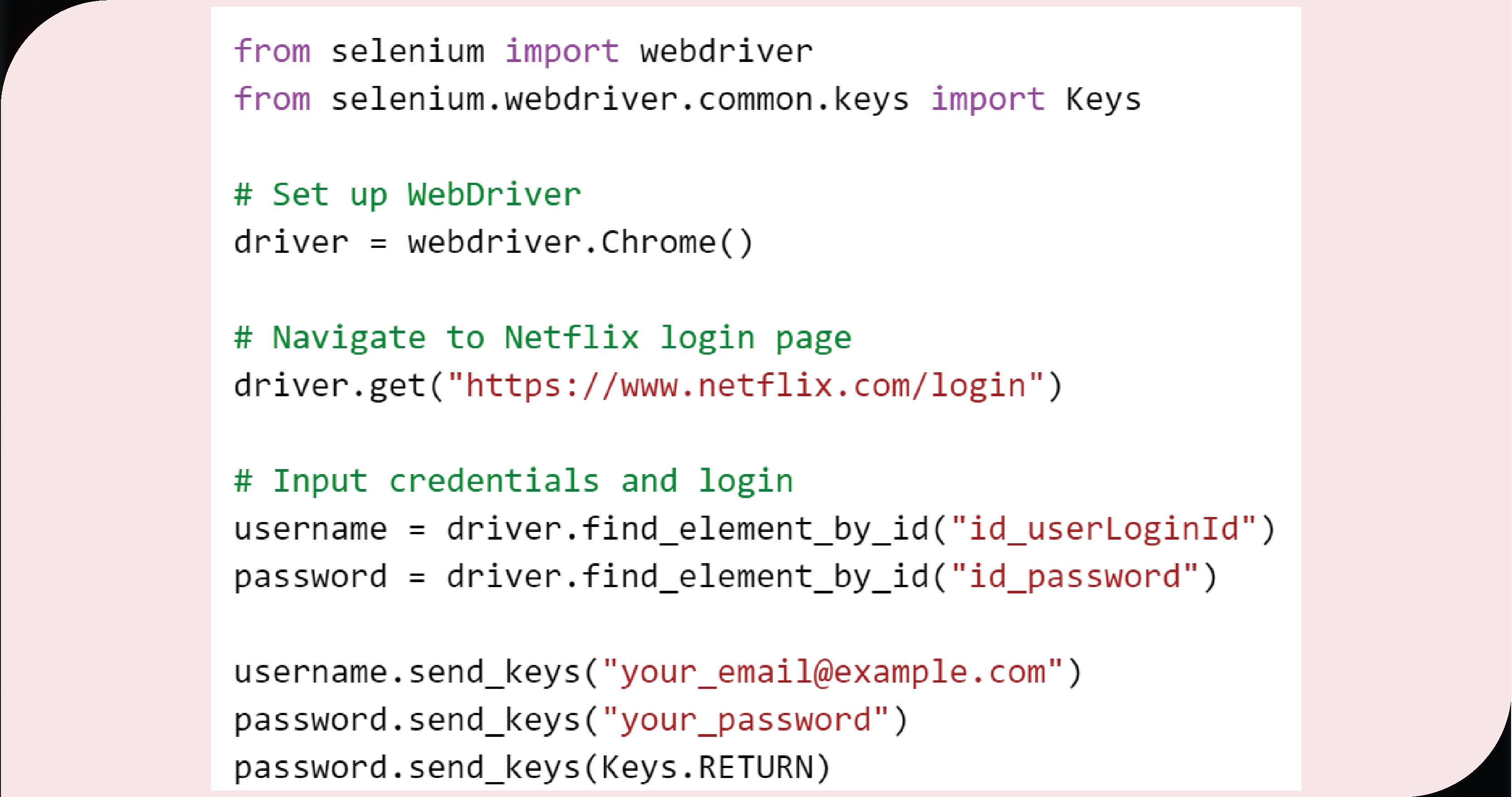
Netflix may require login. Use Python libraries to handle authentication if necessary. For example:
4. Set Up a Python Environment
Install necessary libraries:
pip install requests beautifulsoup4 selenium
5. Manage Anti-Scraping Measures
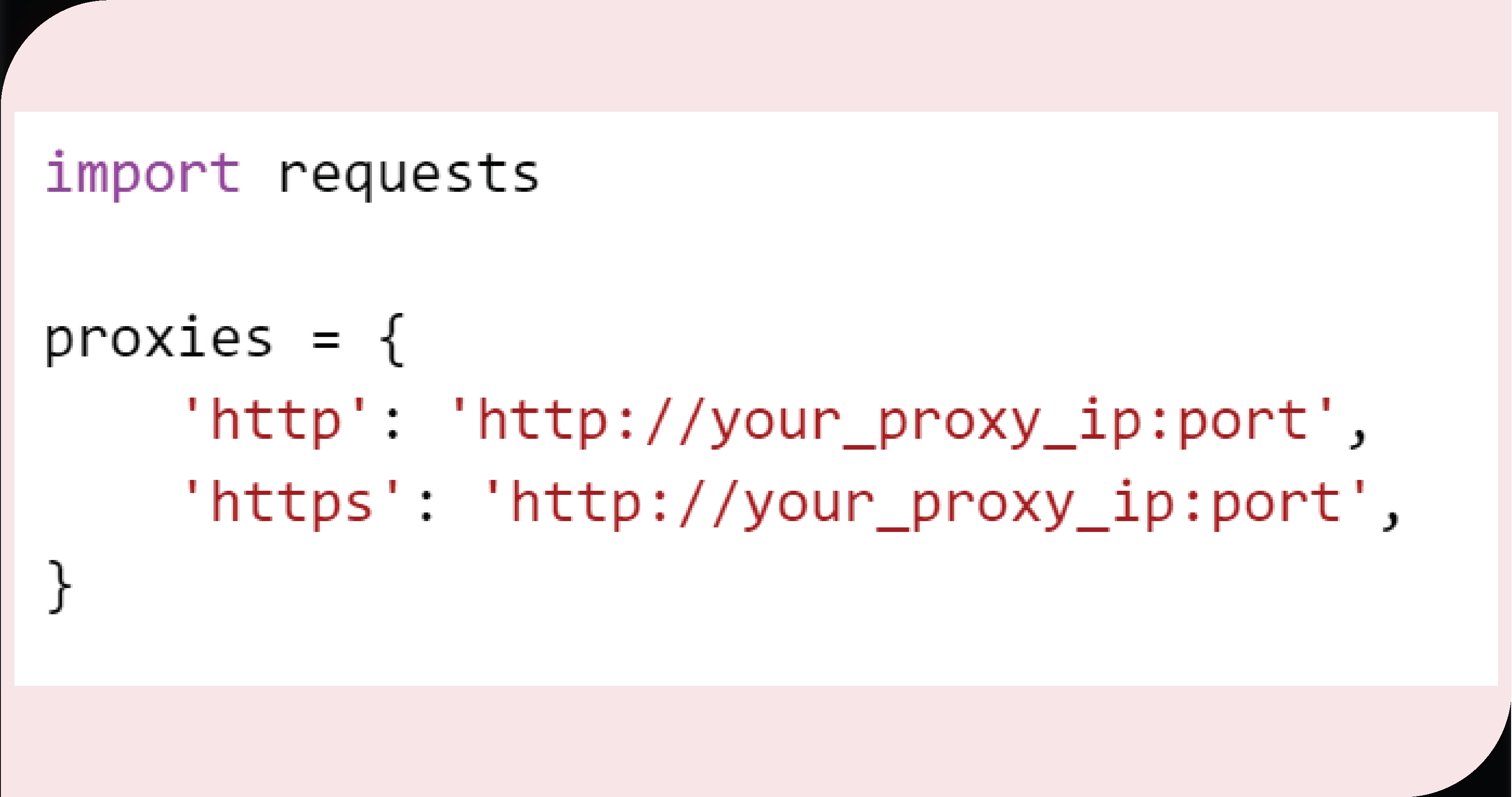
Use proxies or rotate IP addresses. Example of setting up a proxy with requests:
6. Extract Data

Scrape data using BeautifulSoup and requests:
7. Handle Dynamic Content
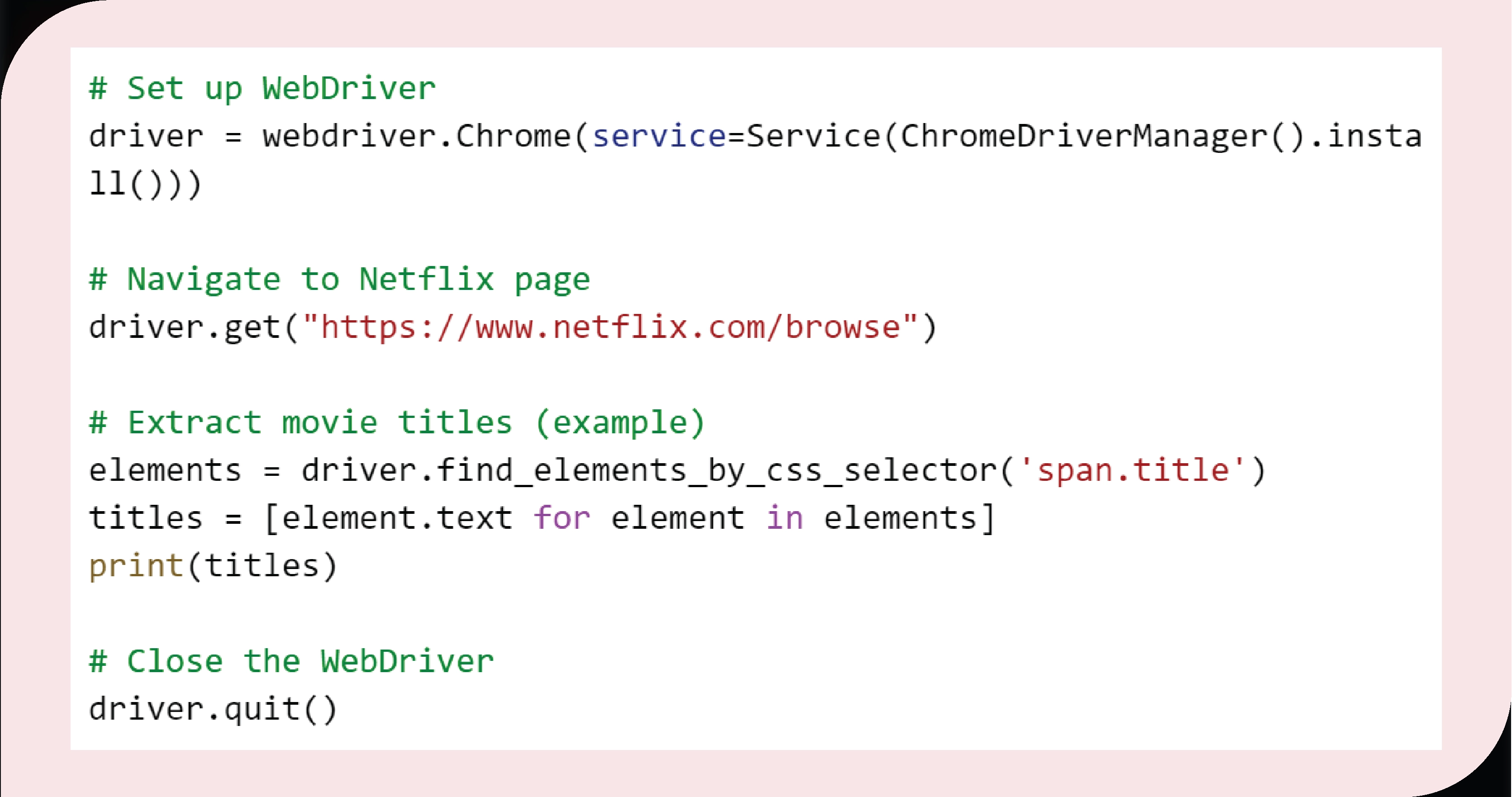
Use Selenium for JavaScript-rendered content:
8. Store Data

Save data to a CSV file:
9. Monitor and Maintain
Regularly check for changes in Netflix’s website structure and update your scraping script accordingly.
10. Respect Legal and Ethical Boundaries
Ensure compliance with Netflix's terms of service and handle data responsibly.
The Future of Netflix Data Scraping

As streaming services evolve, so will the challenges and opportunities in scraping data from Netflix. Advances in machine learning, natural language processing, and artificial intelligence are likely to play a significant role in the future of web scraping, making it easier to extract and analyze complex data sets.
At the same time, platforms like Netflix will continue to develop more sophisticated anti-scraping measures, making it increasingly difficult for unauthorized scrapers to access their data. This ongoing cat-and-mouse game between scrapers and platforms will shape the future of data extraction in the streaming industry.
One emerging trend is ethical scraping techniques, where data is extracted in a way that respects user privacy, complies with terms of service, and is used for legitimate purposes. This approach will likely gain traction as data privacy and security concerns continue to grow.
Conclusion
Scraping Netflix data with Python is a complex and challenging task that requires a deep understanding of the platform's structure, security measures, and ethical considerations. While it can provide valuable insights for developers, analysts, and researchers, it also has challenges.
By carefully navigating these challenges, using responsible scraping techniques, and considering alternatives like Netflix's API, valuable data can be extracted while minimizing the risks. As the streaming industry continues to evolve, so will the techniques and tools used to scrape and analyze data from platforms like Netflix.
Embrace the potential of OTT Scrape to unlock these insights and stay ahead in the competitive world of streaming!