
Introduction
In the modern digital landscape, data is a goldmine. With the continuous evolution of the internet, access to large volumes of data is easier than ever, giving rise to a technology known as data scraping. Among the various platforms that can be scraped, PHILO, a live TV streaming service, offers a treasure trove of information related to user behavior, TV schedules, shows, channels, and more. This article delves deep into the concept of PHILO data scraping, its implications, use cases, legal challenges, and the ethical considerations surrounding the practice.
What is Data Scraping?
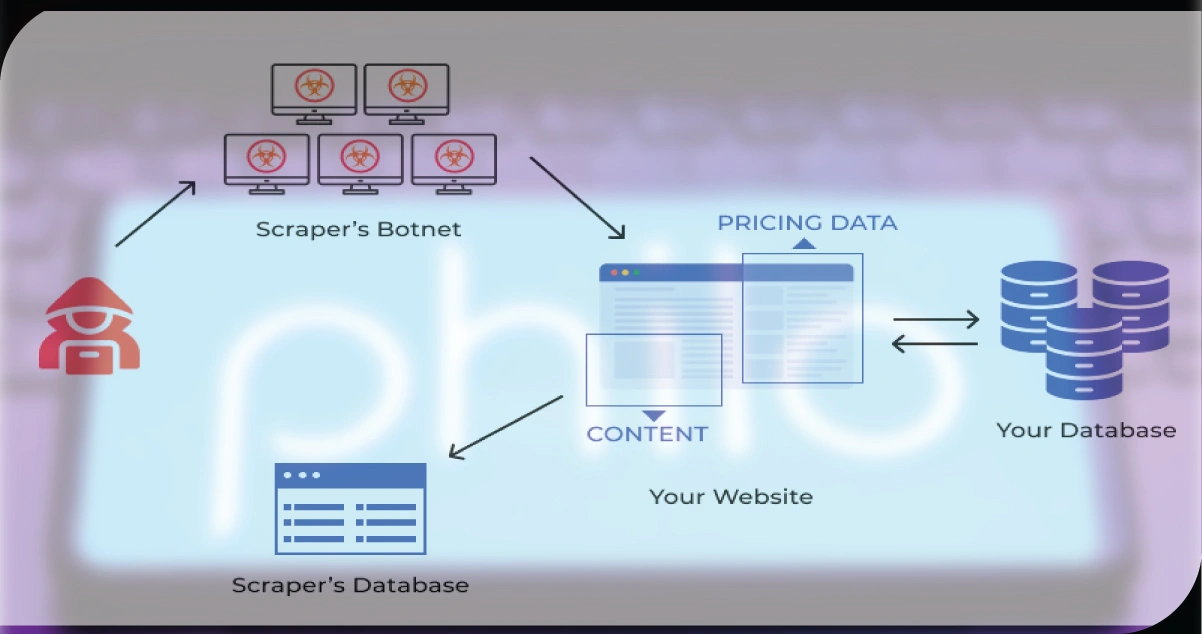
Data scraping is the process of automatically extracting data from websites or applications. This data is often structured in ways that are not directly accessible through standard interactions with the web page or platform. Scraping tools and scripts are designed to navigate through the structured or unstructured data present on a website, extracting information that can be used for various purposes, such as analysis, data science projects, content aggregation, and more.
PHILO data extraction, in particular, refers to collecting data from PHILO, a popular platform that offers over 60 channels of live TV and on-demand content, primarily focusing on entertainment and lifestyle programming. This type of scraping can involve gathering data on shows, schedules, metadata, ratings, and user engagement, providing valuable insights into content trends and viewer preferences.
Use Cases for PHILO Data Scraping

PHILO data scraping offers various applications, including content aggregation, market research, competitor analysis, and personalized recommendations. By extracting valuable insights, businesses can optimize their strategies, enhance viewer engagement, and make informed decisions to stay competitive in the streaming landscape.
1. Content Aggregation and Curation: One of the most common applications of PHILO data collection is aggregating content to provide a comprehensive list of shows, episodes, and airing times across multiple platforms. Media companies or third-party services can build an aggregated guide that helps users find their favorite content across different streaming platforms in one place.
2. Market Research and Analytics: PHILO data contains valuable information about viewer behavior, popular shows, trending content, and peak streaming times. Media companies, advertisers, and entertainment industry analysts can leverage this data to gain insights into the viewing patterns of PHILO's audience. By collecting data using PHILO data scraping services related to the most-watched shows or genres, businesses can adapt their content strategies and advertising campaigns to align with audience preferences.
3. Competitor Analysis: In the competitive landscape of streaming services, understanding what works for one platform can provide strategic advantages. Scrape PHILO data on popular shows and content to understand the preferences of shared audience segments. Insights from such analysis can influence the acquisition of similar shows or the development of targeted content.
4. Recommendation Algorithms: Many streaming platforms rely on sophisticated recommendation algorithms to keep viewers engaged by suggesting shows they may like. By collecting PHILO’s metadata using PHILO data scraper on shows, such as genre, cast, director, or air dates, developers can build or enhance recommendation systems for similar streaming services. This allows platforms to refine their personalization engines and increase viewer satisfaction.
5. Content Licensing and Acquisition: For companies involved in licensing content, understanding which shows are gaining popularity on PHILO can be crucial. By scraping data that indicates viewer ratings, number of streams, or even social media buzz surrounding PHILO content, companies can make informed decisions regarding which shows to acquire or license for distribution.
6. Ad Targeting and Optimization: Advertisers can benefit from scraping PHILO data to understand which shows or genres are popular with certain demographics. This information helps in placing more effective ads during specific shows or in targeting particular audience groups with personalized marketing campaigns. Extract PHILO data to identify trends in viewer behavior. Advertisers can leverage this data to optimize their spend and reach the most relevant audiences with their messages.
The Legal Landscape of PHILO Data Scraping
While web scraping PHILO data provides significant value, it often exists in a gray area legally. Scraping publicly available data is generally considered lawful under certain conditions, but scraping behind authentication mechanisms or bypassing access restrictions can violate a platform’s terms of service and potentially legal statutes. For PHILO data scraping, the legal considerations may be complex and nuanced.
1. Terms of Service (ToS): Like many platforms, PHILO likely has a Terms of Service agreement that governs how users and third parties interact with their content. Most platforms include provisions that restrict or outright prohibit data scraping unless express consent is given. Anyone engaging in PHILO data scraping should carefully review the platform's ToS to avoid potential legal repercussions.
2. Copyright Issues: Since PHILO streams live TV content, some of the metadata associated with shows (e.g., artwork, episode descriptions, etc.) may be copyrighted material. Scraping and then redistributing this data without permission can lead to copyright infringement claims. Companies using scraped data need to ensure that they are not violating intellectual property rights.
3. Computer Fraud and Abuse Act (CFAA): In the U.S., the CFAA criminalizes unauthorized access to computer systems. Data scraping that involves bypassing access restrictions (such as login credentials or captchas) on PHILO's platform may be considered illegal under the CFAA. The legal standing of scraping under this act has been debated, but it remains a significant concern for anyone engaging in large-scale data collection.
4. Data Privacy Laws: Depending on the scope of the data being scraped, there may be data privacy concerns to consider. For instance, if the scraping includes any form of user- generated content, viewer comments, or user behavior patterns, it could infringe on privacy laws such as the General Data Protection Regulation (GDPR) in Europe or the California Consumer Privacy Act (CCPA) in the United States. Such laws impose strict requirements on how companies collect, store, and use personal data, even if it is scraped from a public source.
Ethical Considerations in PHILO Data Scraping

In addition to the legal concerns, there are ethical considerations surrounding data scraping. Companies must balance the potential benefits of scraped data with the responsibility to respect user privacy, platform terms, and the overall digital ecosystem. Some of the key ethical challenges include:
1. Respecting Platform Resources: Data scraping, especially if done at scale, can put a significant load on a platform’s servers, potentially affecting the service for legitimate users. Scrapers should implement strategies such as rate-limiting and avoiding excessive requests to minimize the impact on the platform’s performance.
2. Transparency and Consent: One of the fundamental ethical principles is gaining proper consent. If data scraping involves gathering information from users (such as viewing habits or ratings), transparency about how the data will be used and ensuring that users are informed is essential. Collecting data without explicit consent can lead to a loss of trust and negative brand perception.
3. Accuracy and Fairness: When scraped data is used for analysis or to inform business decisions, it is crucial to ensure that the data is accurate and representative of the broader context. Misinterpreting scraped data or using it in a biased way could lead to flawed decisions, inaccurate predictions, or the dissemination of false information.
4. Security Concerns: Improperly managed scraping activities can expose the platform or scraper to cybersecurity risks. Scraping often involves interacting with web elements like APIs or JavaScript functions, and improper handling of these interactions can result in data leaks or unauthorized access to sensitive information.
Conclusion
PHILO data scraping offers substantial opportunities for various industries, from content aggregators and market analysts to advertisers and competitors in the streaming space. However, with great potential comes a host of legal, ethical, and technical challenges. Navigating these challenges requires a careful balance of compliance with laws, respect for platform terms, and consideration for user privacy.
While data scraping continues to be a valuable tool in the modern data-driven landscape, it is crucial for organizations and individuals involved in scraping PHILO or similar platforms to remain vigilant about the ethical implications and legal requirements, ensuring their practices not only benefit their goals but also maintain integrity within the digital ecosystem.
Embrace the potential of OTT Scrape to unlock these insights and stay ahead in the competitive world of streaming!