
In todays data-driven landscape, extracting data from streaming platforms such as Hulu has become highly valuable for competitive analysis, research, and data intelligence purposes. Hulu, a leading video streaming service, has vast movies, TV shows, and original content collections. However, gathering information on their content manually is challenging, so automating this process with tools and APIs becomes essential.
This article explores the top tools and libraries for efficiently scraping Hulu with API Data. We will discuss various APIs, libraries, and web scraping tools that can extract Hulu's data seamlessly and ensure the process remains within ethical and legal boundaries.
Understanding the Role of APIs in Scraping Hulu
Application Programming Interfaces (APIs) are crucial for Hulu with API Data Collection. An API is an intermediary that allows different software to communicate with Hulu's databases and servers without violating terms of service (TOS). Many public APIs are available to access streaming data, but sometimes custom-built APIs are needed to fetch specific data types from Hulu.
Web scraping and API-based data extraction are different. Scraping refers to collecting structured data from the web, typically HTML content. However, scraping APIs allows a more refined way of obtaining structured data in formats like JSON or XML, which can be more accessible and scalable than traditional web scraping.
Role of Hulu with API Data Scraping Services
As a significant player in the streaming industry, Hulu offers a vast range of content, from movies to TV series, attracting millions of viewers worldwide. The role of Hulu with API Data Scraping Services lies in the potential to unlock valuable data from its platform. Businesses and researchers can extract critical information such as show ratings, viewer reviews, trending content, and user interaction data by utilizing Hulu with API Data Scraper. This data helps companies understand audience preferences, content popularity, and emerging viewing trends.
Scrape Hulu Data with API services is particularly useful for businesses looking to optimize their marketing strategies, make data-driven decisions, and enhance personalized user recommendations. By analyzing the vast amount of data available on Hulu, companies can fine-tune their content strategies, identify gaps in the market, and better position themselves in the competitive streaming space.
Moreover, scraping Hulu data through APIs provides insights into competitor analysis, allowing stakeholders to track what content is performing well and where opportunities for growth lie. However, its essential to remain compliant with legal and ethical guidelines when scraping data from Hulu, as misuse can lead to violations of terms of service. Properly managed, Hulu with API Data Scraping Services can significantly benefit businesses seeking to thrive in the dynamic streaming industry.
Why Scrape Hulu with APIs?
Web Scraping Hulu with API Data can provide access to:
- Content Metadata: Details of movies, shows, cast, genres, release dates, and ratings.
- User Reviews and Ratings: Gathering user ratings to conduct sentiment analysis.
- Subscription Plans and Offers: Extracting pricing details, different subscription options, and promotions.
- Trending Shows and Recommendations: Gathering Hulu's trending shows or user-specific recommendations for a deeper analysis.
Let's dive into the top tools and libraries for scraping Hulu with APIs.
1. Scrapy

Overview:
Scrapy is a robust open-source Python framework for scraping websites and APIs. It allows users to efficiently extract large amounts of data from dynamic and static pages. Scrapy can automate metadata extraction for Hulu's shows, movies, and other media.
Key Features:
Usage:
Limitations:
Example Code:
2. BeautifulSoup

Overview:
BeautifulSoup is a popular Python library for parsing HTML and XML documents. Due to its simplicity, it is widely used for web scraping. While not an API client, BeautifulSoup can be combined with requests or other HTTP libraries to scrape Hulu's web pages effectively.
Key Features:
Usage:
Limitations:
Example Code:
3. Selenium

Overview:
Selenium is a web automation tool commonly used to scrape dynamic websites. It is especially effective for scraping websites that load content dynamically using JavaScript, such as Hulu. Selenium mimics user interaction by automating a web browser.
Key Features:
Usage:
Limitations:
Example Code:
4. Requests Library
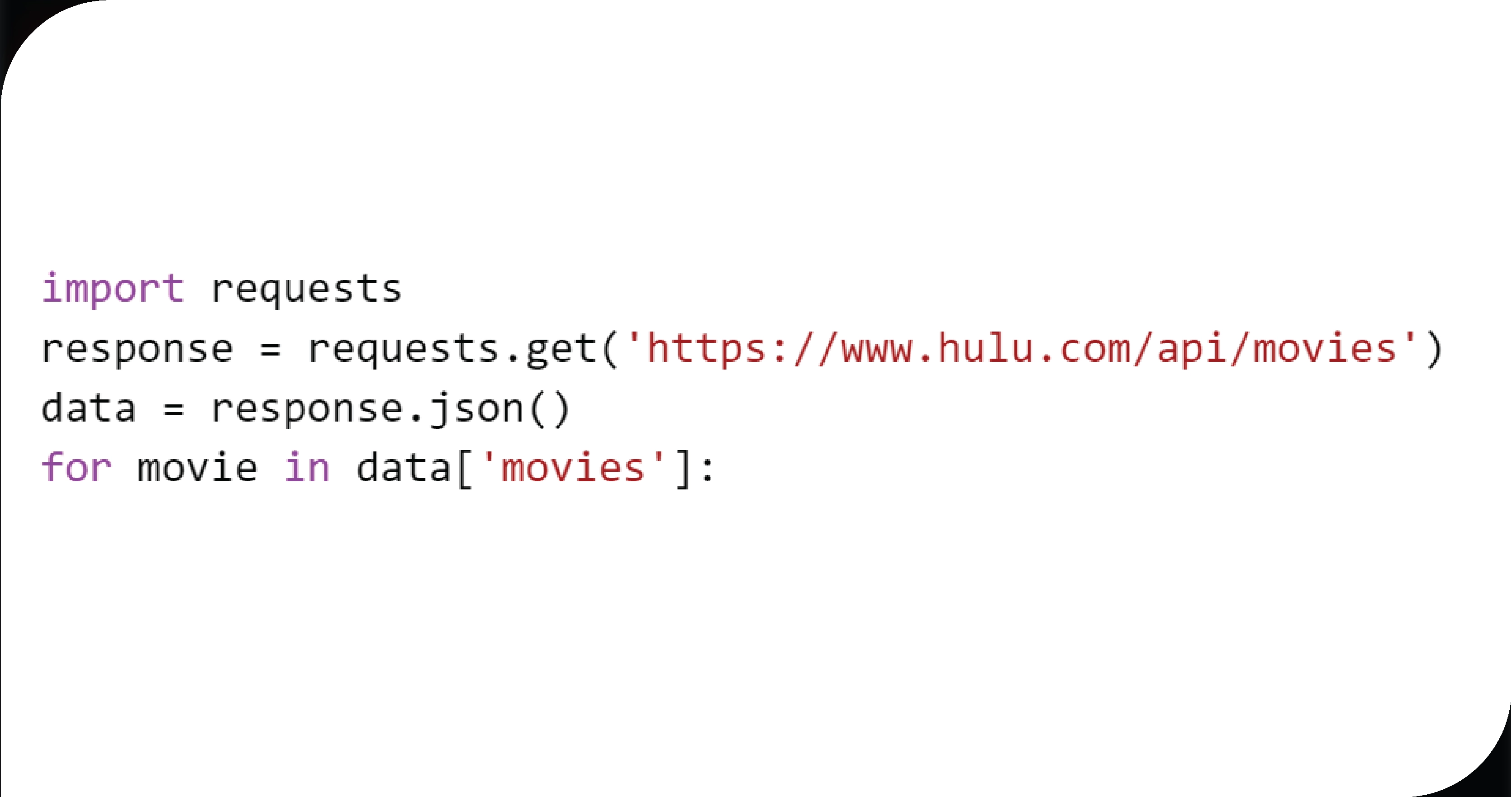
Overview:
The Requests library is one of Python's most well-known libraries for making HTTP requests. Requests can efficiently retrieve data in JSON or XML format from Hulu's servers when combined with APIs. It can also scrape Hulu's content if public APIs are available.
Key Features:
Usage:
Limitations:
Example Code:
Conclusion : Hulu with API Data Extraction requires using a blend of libraries and tools depending on the complexity of the task and the type of data you wish to extract. Tools like Scrapy, Requests, and Selenium allow developers to scrape data programmatically.
It is essential to ensure compliance with Hulu's terms of service while scraping and to utilize scraping ethically. With the right tools and techniques, extracting data from Hulu can significantly enhance business intelligence, research, and content analysis efforts.
Embrace the potential of OTT Scrape to unlock these insights and stay ahead in the competitive world of streaming!